


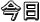
では具体的な話に入る前に前章のおさらいを少ししておきましょう。
セーブデータ 経験値 = 1000 |
今上のようなセーブデータがあったとしましょう。
セーブデータを不正改竄し、経験値を2000にしてみます。
セーブデータ 経験値 = 2000 |
ファイルの値を書きかえるだけですから、誰にでも出来る簡単なことです。
しかし、以下のようなセーブデータならどうでしょう。
セーブデータ 経験値 = 1000 ハッシュ値 = 25 |
ハッシュ値は経験値に依存して決定される値です。
つまり、経験値を変更したらハッシュ値も変更しないとバレるんですが、改竄する側としては、いくらに変更していいか分かりません。
試しに、経験値だけ2000に変更してみましょう。
セーブデータ 経験値 = 2000 ハッシュ値 = 25 |
もしこのようなデータが入っていたら私には改竄されたことが分かります。
何故なら、私は「ハッシュ値は経験値を39で割った余り」という決まりを作っていたからです。
1000を39で割った余りは25ですが、2000を39で割った余りは25ではなく11です。計算が合わないので、改竄されたことが分かりました。
このようにセーブデータに依存して変更する値を一緒に記録することで、セーブデータの改ざんが発見出来ます。
今回は39で割ったあまりということで39回試せばハッシュ値を見つけることが出来ましたが、これから紹介するハッシュ値計算アルゴリズムであるMD5は
340282366920938463463374607431768211456通りのパターンがあるので、現実的に総当たりで試すことは不可能です。
ここまでが前回のおさらいです。
MD5は一種の乱数みたいなものです。
シードとなるキーを最初に与えることで、訳の分からない一意の初期値が決まります。
そこでデータを一つずつ与えるごとにハッシュ値は一つずつ訳の分からないらない値に変化します。
しかし、この一見訳の分からない値(例えば9882337128219832736261873283717みたいな値)は、同じ手順で計算すると必ず同じ値になります。
今、乱数で言うシードにあたる、初期値を与える「カギ」の値を「39」だとしましょう。
39で、MD5の初期値をセットします。
そして、経験値である「1000」の文字列を一文字ずつMD5の計算関数に渡します。
「1」を渡すと、またハッシュ値は変化し、
「0」を渡すと、またハッシュ値は変化し、
「0」を渡すと、またハッシュ値は変化し、
「0」を渡すと、またハッシュ値は変化します。
最終的に出来上がった一見訳の分からない膨大な数の値をハッシュ値として使います。
改竄を確認する時は、先ほどと同じ手順で、「39」で初期化し、「1,0,0,0」の順でデータを渡してやります。
すると、先ほど計算したハッシュ値と同じ値が出てくるはずです。
これが「2000」のように経験値が改竄してあれば計算されるハッシュ値も異なるので、改竄が発見出来ます。
ここでMD5のアルゴリズムを理解して実装するのは困難ですが、
windows.hには既にハッシュ値を計算するライブラリが存在します。
MD5 CryptGetHashParam で検索すると、MD5を使ったハッシュ値の計算方法が出てきます。
こうして算出したハッシュ値をセーブデータと共に記載し、改竄チェックを行って下さい。



- Remical Soft -